I Thought I Needed Better Prompts. I Needed a System.
2026-01-17
I have a busy family life and no time to watch hours of YouTube tutorials. Also, I find the information density very sparse and extracting the information very time-consuming. My “Neo from the Matrix” fantasy has always been to have knowledge injected directly into my brain—skipping the medium and going straight to the data. So my wish formulated that I would like to have the information extracted, so I can expose my brain to the compacted knowledge and speed through all the knowledge I would like my brain to have consumed.
Last summer, I decided to build my way out of that friction.
The Initial Win and the Illusion
My plan was straightforward and, at the time, I didn’t even think of it as an “application”. I just wanted to feed video transcripts to an AI, extract the information into clean Markdown, and push those files to a Git directory. From there, a static site generator and some GitHub Actions would turn the data into a readable blog post. I wanted something I could consume via a browser or RSS feed, fully replacing the need to watch the video.
The first results were exceptionally good—the AI captured structure and nuance far better than I expected. For a brief moment, it felt like I had solved the problem with just a few clever prompts.
Where Reality Disagreed
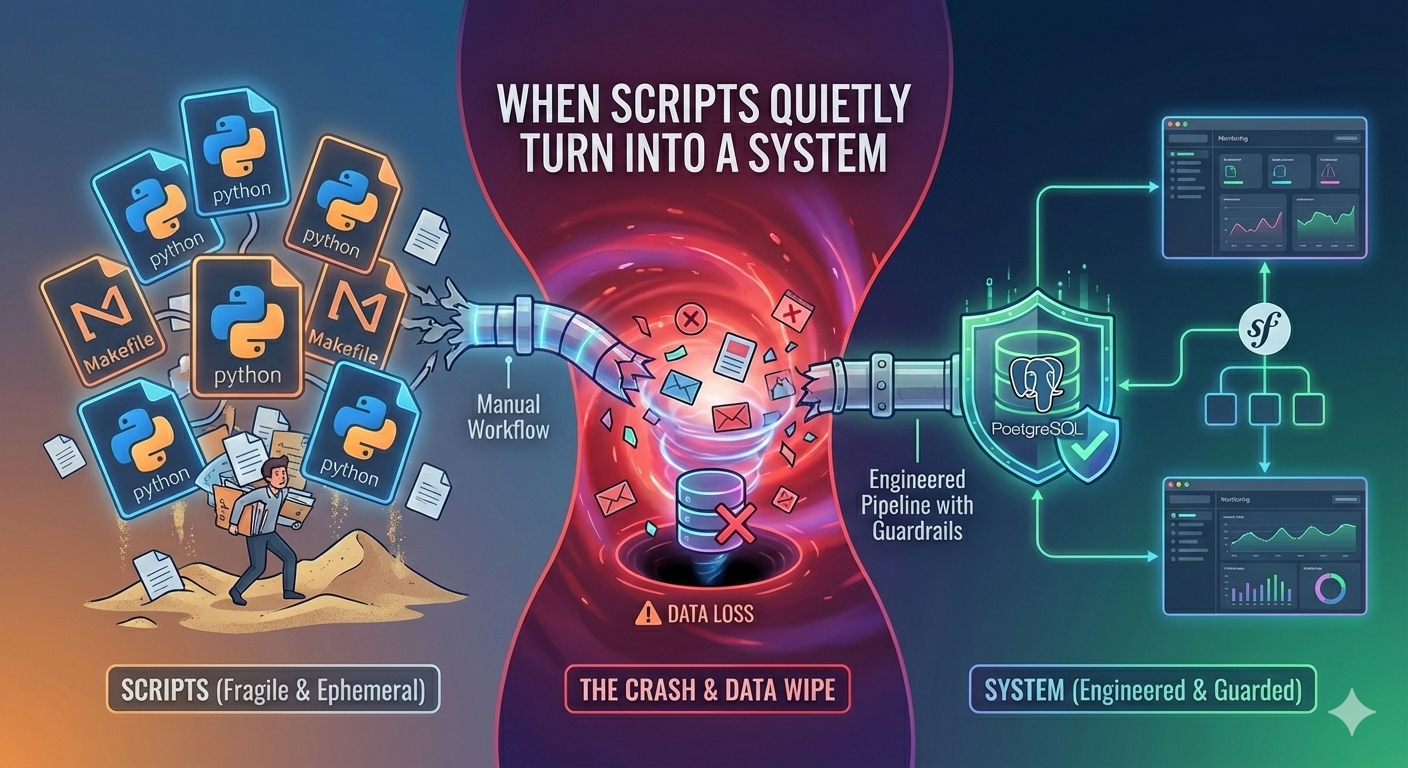
The friction started almost immediately, and it wasn’t an AI problem—it was a manual effort problem. I found myself trapped in a boring, repetitive cycle of copying video IDs into a Makefile and running Python scripts manually. I was playing “human cron job”.
As I processed more content, the Markdown files started piling up. Managing the metadata, searching through the directory, and deduplicating entries became significantly harder than generating the content itself. That was the moment I realized that a database wasn’t just a “nice-to-have” feature; it had to be the center of the project.
From Script to System
The turning point was realizing that I didn’t want a better script or better prompts; I wanted an agentic system that could discover, ingest, analyze, and publish content without my intervention. I had to move beyond “generating text” and start “operating a workflow”. This forced me to shift my thinking toward maintainability and long-term stability.
While I started with Python-based frameworks, I quickly hit a wall of “vibe-trash”—a pile of scattered scripts that were easy to write but impossible to reason about weeks later. I eventually moved the entire project to PHP and Symfony. Moving to my “native” environment allowed me to own the orchestration layer and build something I could actually debug when things went wrong.
To ensure the system remained safe and queryable, I moved away from ephemeral files toward a more robust stack: PostgreSQL with pgvector for embeddings and Neo4j for knowledge graphs. This wasn’t about over-engineering; it was about building a foundation that could handle the consequences of state, consistency, and scale.
Symfony AI is a set of components that integrate AI capabilities into PHP applications, providing a unified interface to work with various AI platforms like OpenAI, Anthropic, Google Gemini, Azure, and more.
Engineering Over Magic
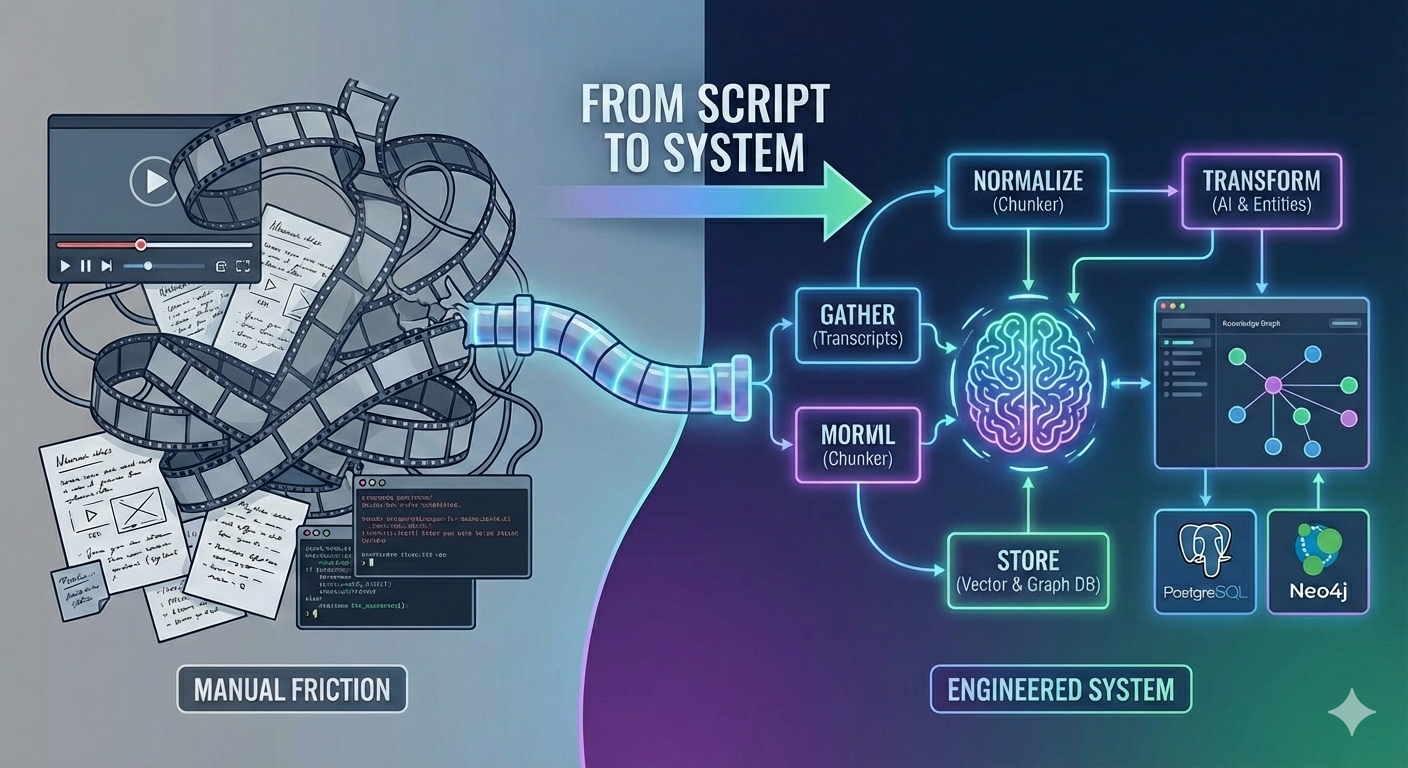
Here’s what became clear: “knowledge extraction” sounds like a single AI task. It’s not. It’s a pipeline with distinct stages:
- Gather – Fetch transcripts, manage metadata
- Normalize – Chunk at semantic boundaries, disfluency Removal
- Transform – Extract entities and relationships
- Store – Vectors and graphs
- Retrieve – Routed search methods
Most of these stages have nothing to do with AI.
They are fundamental, necessary steps. I stopped looking for the “perfect model” and started building a TranscriptChunker to preserve timestamps and a database schema that could actually handle metadata.
What surprised me was that AI is most effective when it is given the smallest possible job. I found that chaining specific, isolated AI calls produced far more reliable results than one massive “do everything” request.
The Realization: Plumbing Over Prompts
AI fails silently and gracefully. Without proper tracing, I couldn’t tell the difference between an output that “looked good” and one that actually captured the knowledge I needed. I saw that if I couldn’t trace exactly how a piece of knowledge was extracted, I didn’t have a system—I just had a demo.
The architecture surrounding the AI—the database design, the way I decided to split chunks of text, the preservation of metadata—is where the real engineering happens. These are application problems, and they are where most AI projects quietly fall apart.
I am still figuring out the optimal patterns for this. Structured guidance is scattered across half-finished repos and old blog posts, and I’m still learning how to search for the “right” way to build these systems. But my focus has permanently shifted: I care less about individual prompts and more about the traceable, repeatable system that makes those prompts work.
That is the work that actually scales—and the only way I’ll ever get that “Neo” style knowledge injection.